| - Spark 3.0은 3,400개 이상 JIRA 해결 - Spark SQL, Spark Core 중심으로 버전업 - Hadoop3 지원 |

01. Adaptive query execution를 위한 새로운 프레임워크(AQE)
02. Nested Column Pruning
03. Spark를 위한 Accelerator-aware task 스케줄링
01. AQE
- JIRA: https://issues.apache.org/jira/browse/SPARK-31412, https://issues.apache.org/jira/browse/SPARK-11150
Spark 2.0 버전까지 Cost-based Optimzer를 사용하였는데 이 방법의 단점은 데이터의 통계가 있어야 퍼포먼스가 좋고 데이터의 통계가 최신화되어있어야 한다는 단점이 있었다.
이 때문에 쿼리 플랜을 세울때 비용을 잘못 추정하는 경우가 많았다.
이번 릴리즈에서 AQE라는 Adaptive Query 실행 프레임워크를 도입하여
완성된 쿼리 플랜에서 정확한 통계를 수집한 뒤 Optimizer와 Planner의 기존 규칙을 사용하여 쿼리 실행 계획 최적화한다.

Spark Catalyst Optimizer History
Spark 1.x: Rule-Based Optimizer
Spark 2.x: Rule + Cost-Based Optimizer
Spark 3.x: Rule + Cost + Runtime Based Optimizer (AQE)
01) 셔플 파티션을 동적으로 병합
Spark에서 쿼리를 실행할 때 셔플은 쿼리 성능에 큰 영향을 끼친다.
Shuffle의 주요 속성은 파티션의 수인데 가장 최적화된 파티션의 수는 데이터의 크기, 쿼리 단계마다 다르기 때문에 이 수를 정확하게 조정하기 어렵다.
- 파티션이 너무 적으면 각 파티션의 데이터 크기가 매우 커질 수 있으며 이러한 큰 파티션을 처리하는 작업은 쿼리 속도 영향
- 파티션이 너무 많으면 각 파티션의 데이터 크기가 매우 작을 수 있고 셔플 블록을 읽기 위해 작은 네트워크 데이터를 많이 가져와서 비효율적인 I/O로 인해 쿼리 속도가 느려질 수 있고 작업이 많으면 Spark 작업 스케줄러에 더 많은 부하
이를 해결하기 위해 AQE에서 데이터를 셔플링할때 작은 셔플 파티션을 병합하여 다른 파티션의 크기와 비슷하게 만들어준다.


02) 동적으로 Sort merge join을 Broadcast Hash Join으로 전환
런타임 통계 기반으로 소프트 병합 조인을 브로드캐스트 해시 조인으로 변환할 수 있다.
과잉 분할 후 감속기의 수를 줄일 수 있고 런타임에 skew 조인 처리도 가능하다.
spark.sql.autobroadcastjointhreshold
이 옵션을 통해 성능 조정을 할 수 있는데 정확하기 조절하기 어려운 이유는 OutOfMemory Exception이 발생하고 성능이 저하될 수 있다.
작동하더라도 데이터 워크로드에 민감하기 때문에 시간이 지날 수록 유지 관리가 어려운데 이유는 아래와 같다.
- 통계가 누락되거나 최신이 아닐 수 있음
- 파일이 압축
- 파일 형식은 열 기반이므로 파일 크기는 실제 데이터 볼륨을 나타내지 않음
- 필터가 압축될 수 있음
- 필터에도 Blackbox UDF 포함될 수 있음
- 전체 Query Segment가 크고 복잡할 수 있으며 이때문에 Spark의 실제 데이터 볼륨을 추정하기 어려움

AQE는 런타임에 Sort merge join을 Broadcast hash join으로 변환
1. Leave Stage 실행
Query Segment를 구체화하는 셔플 연산자에서 통계 쿼리
2. 통계 정보를 바탕으로 나머지 쿼리 플랜을 최적화하고 조인 알고리즘을 Sort merge join에서 broadcast hash join으로 변경
03) Skew Join을 동적으로 최적화
Spark에서 Skew와 올바른 쿼리를 찾아 스큐 값을 별도로 처리 가능하다.
Skew로 문제가 생기는 경우는 두 데이터를 조인해야 하는데 서로 데이터 양의 차이가 지나치게 많이 나거나 전체 데이터에 Null이 있는 경우 사용자가 데이터의 분포를 미리 파악하고 수동으로 분배해주는 작업이 필요했다.
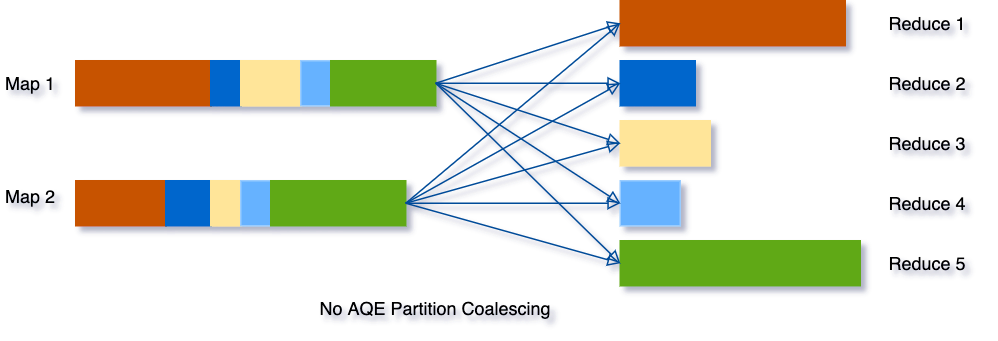
이번 AQE는 이 작업을 자동으로 분배해주어 Reduce 작업의 수를 줄이고 끝나는 시간도 비슷하게 만들어 준다.

02. Nested Column Pruning
- JIRA: https://issues.apache.org/jira/browse/SPARK-25603
Nested Column(Json, Map)에 대해 column pruning을 적용하고 parquet에만 적용되던 기존 nested column pruning을 다른 format(orc)에도 적용되는 기능이다.
최근 비정형 데이터가 늘어나는 추세에 맞춘 것으로 Spark sql도 비정형 쿼리 질의를 지원하게 되었다.
03. Spark를 위한 Accelerator-aware task 스케줄링
- JIRA: https://issues.apache.org/jira/browse/SPARK-24615
Spark가 GPU를 지원하기 위한 작업으로 Standalone, YARN, Kubernetes를 클러스터 스케쥴러로 사용할떄 GPU 리소스도 할당할 수 있도록 도와주는 프로젝트이다.
이외에도 Hadoop3에 발맞추어 Hadoop3에 대한 지원도 있고 꽤 흥미로운 기능들이 추가되었다.
관심이 있다면 아래 Spark 릴리즈 노트를 확인해보면 좋을 것 같다.
// 자료 참고 및 출처
https://spark.apache.org/releases/spark-release-3-0-0.html
https://databricks.com/session_na20/deep-dive-into-the-new-features-of-apache-spark-3-0
https://nephtyws.github.io/data/whats-new-in-spark-3/
https://dalsacoo-log.tistory.com/entry/Spark-30-%ED%95%9C-%EB%B2%88%EC%97%90-%EC%A0%95%EB%A6%AC%ED%95%98%EA%B8%B0
https://databricks.com/blog/2020/05/29/adaptive-query-execution-speeding-up-spark-sql-at-runtime.html'Spark' 카테고리의 다른 글
| 실시간 처리 프레임워크 비교 (0) | 2021.03.25 |
|---|