Schema

Primary Key의 역할
- 각 row를 고유하게 식별
- PK를 이용한 쿼리 검색 지원
- index
- tablet의 길이를 줄여줌(height)
- near-primary-key 순서로 insert 가능
병합 압축(Merge Compaction)

tablet에서 하나의 단일 rowset으로 여러 개의 rowset을 결합
성능을 향상시키려면 아래 조건 만족해야함
- tablet의 높이(height) 줄이기
- row 조회 성능 개선(write, read 모두)

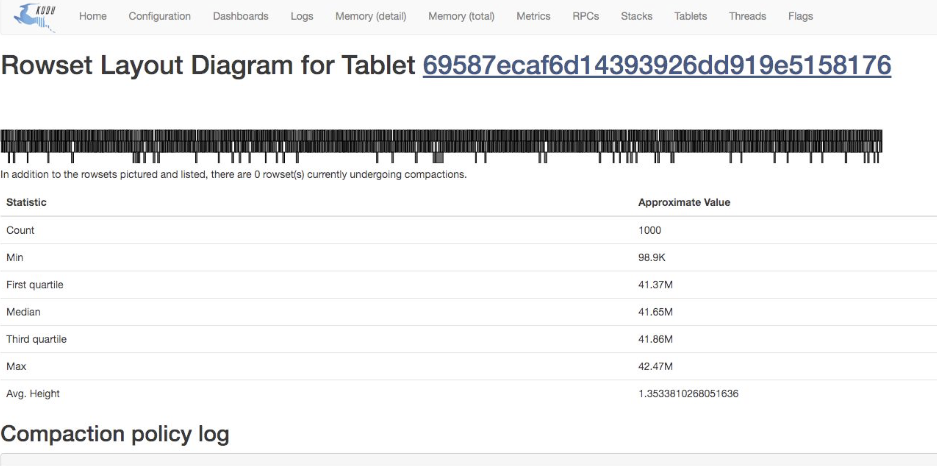
동일한 tablet 기준 첫번째 그림의 경우 height가 균일하지 않은 상태이고 두번째 그림은 균일한 상태
조회나 기타 성능 면에서 두번째 그림이 유리
Schema 예시(최적화)
- id, timestamp 컬럼
- row는 timestamp 순서대로 종렬
- 단일 id의 row를 선택하는 쿼리
- select * where id="akjwsd1j31k3jl";
- id는 랜덤 고유한 식별자라는 제한 (이런 케이스엔 압축이 잘되지 않음)




| 구분 | 설명 | 장단점 |
| id, timestamp | id 기준으로 정렬 | - 공간 사용률 좋음 - id 관련 조회 쿼리 속도 빠름 - insert 느림 |
| timestamp, id | timestamp 기준으로 정렬 | - 공간 사용률 낮음 - id 정렬이 되지 않고 데이터 압축 성능 떨어짐 -insert에 최적화 |
두 방법 모두 단점이 있으므로 이를 보완하려면 timestamp_prefix를 활용한다.


Kudu가 hardware를 어떻게 사용할까?
Disk
WAL directory: WAL과 metadata를 위한 단일 디스크
- write-ahead log와 각 tablet의 metadata를 저장하는 단일 디렉토리
- 성능이 좋으려면 이 디스크가 중요(주로 SSD, NVME 드라이브)
Data directories: on-disk rowset을 위한 JBOD(Just a bunch of disks)
- 여러 개의 data directory들이 tablet replica들에 의해 공유
- 성능 중요성이 덜함
- 대부분 background taks들에 의해 write 작업
- kudu가 충분히 빠르게 flush하고 압축하기 위해 중요하긴 함

Memory
MRS, DMSs (write 동작이 있을때)
- kudu의 메모리가 부족하면 MRS나 DMS를 disk로 공격적으로 flush
DRS마다 사용되는 memory
- Cfiles 추적, bloom filters, indexes 등을 갖고 있기 위해 필요
- tablet 서버마다 수백개의 DRS를 보유
Scaling Memory
| disk의 TB당 메모리 (on-disk 상태 추적을 위해 유지하기 위해) |
1.5GB per 1TP of on-disk data |
| Write(MRS, DMS) | 최소 128MB per Hot replica |
| Scans(조회) | 스캔이 무거운 테이블을 위해 core, 컬럼당 256KB |
| Block cache | 기본 512MB |
Caching
Block cache
- Cfiles의 조각, bloom filter, index block을 저장하는 LRU 캐시
- 기본값 512 MB
- 잦은 조회, insert에 유용
- disk로부터 읽어야하는 긴 scan에는 유용하지 않음
참고
1) 2019년 클라우데라 웨비나 세션 중 "Apache kudu를 이용한 실시간 워크로드 최적화"
'Kudu' 카테고리의 다른 글
| [Kudu] Apache Ranger로 권한 제어 (0) | 2021.04.13 |
|---|---|
| [kudu] 3편 - Scaling cluster (0) | 2021.04.06 |
| [kudu] 1편 - write, read, partition (0) | 2021.03.30 |
| [기초] Kudu 기본 개념 (0) | 2021.03.30 |
| [사례] kudu X 카카오뱅크 (0) | 2021.03.29 |